Our mission
The mission of the Big Scientific Data and Text Analytics Group (BSDTAg) is to advance the state-of-the-art and develop new technologies powered by AI in the area of the machine processing of scientific information.
We identify with the use of AI for the public good. We carry out research to empower the next generation of researchers to be able to more effectively access, understand, interpret and build on open knowledge and to do so in line with the principles of open science.
More specifically, we:
- apply AI to improve ways in which research is conducted;
- develop novel technologies enabling systematic analysis of research data and literature;
- create services to improve access to scientific information for all;
- do research on research;
- support the transition to and raise awareness of the benefits of open research;
- work with companies to help them derive value from research data and scientific information in areas as diverse as analysing trends, detecting misinformation and plagiarism detection.
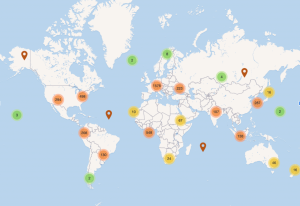
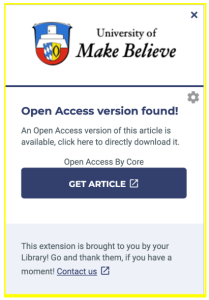
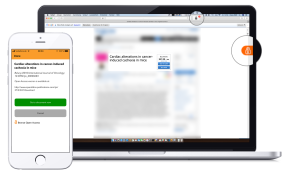
We firmly believe that scientific knowledge should be available to all, not just a privileged few. Open Access and Open Science are key drivers for equal access to information for everyone. Through our CORE service, we deliver credible scientific information to tens of millions of people from more than 260 countries each month (SDG 10: Reduced Inequalities). Additionally, Open Science is a key component in helping to ensure everyone has equal access to robust scientific knowledge at every level, from high school students to post-doctoral researchers (SDG 4: Quality Education)
There is a current crisis on a global scale with mis-information having an impact in many areas from politics to climate change and beyond. A well informed society with access to reliable, trustworthy information is a cornerstone of a strong democracy (SDG 16: Peace, Justice and Strong Institutions). Our group provides free access to the largest collection of Open Access, peer-reviewed, scientific literature thus helping to ensure that accurate, reliable information is available to all. We are also developing AI powered solutions for the public good, helping to empower people to form their opinions and take decisions based on sound scientific evidence, protecting against conspiracy and mis-information in a wide range of areas, including medical, clinical and bio-medical research (SDG 3: Good Health & Wellbeing).